As a developer working in SQL Server, I often have to remove duplicate data from the tables to free up space in our database. In this article, I will discuss different approaches to this task.
Approach-1: Using the ROW_NUMBER() Function
We can use the ROW_NUMBER() Function for this purpose.
Let us consider the example below, where we will remove the duplicate records from the USAHome table.
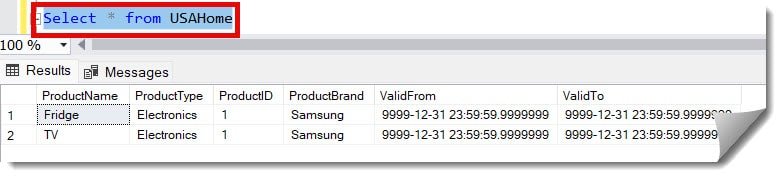
Before executing the script, let me run the query below to check all the records in the USAHome table. The screenshot below shows many duplicate records.
Select * from USAHome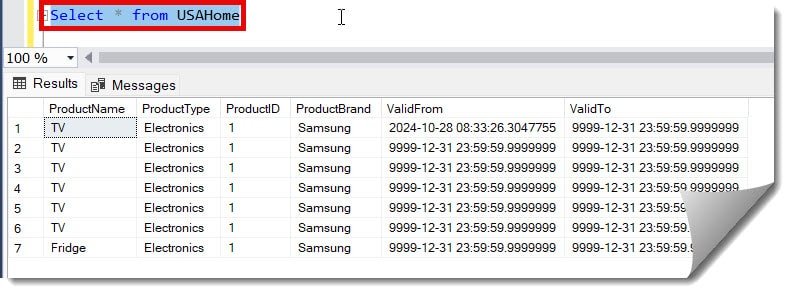
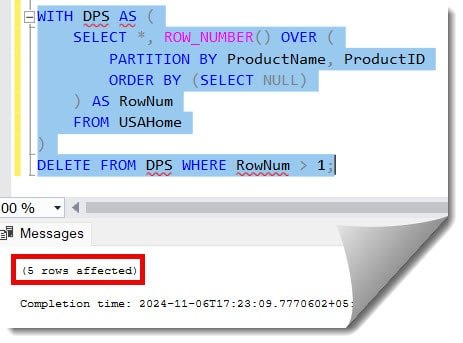
Now, let us execute the below query to remove the duplicates from the USAHome table.
WITH DPS AS (
SELECT *, ROW_NUMBER() OVER (
PARTITION BY ProductName, ProductID
ORDER BY (SELECT NULL)
) AS RowNum
FROM USAHome
)
DELETE FROM DPS WHERE RowNum > 1;The query was executed successfully, and 5 duplicate rows were deleted, as shown in the screenshot below.
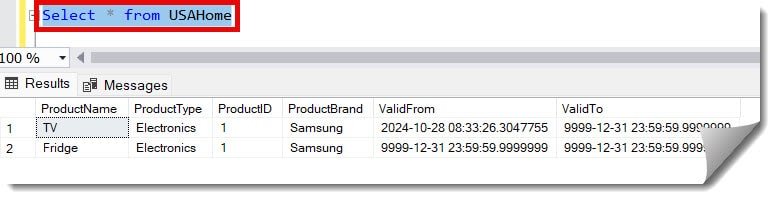
Now, to cross-check, let us execute the below select query again. You will see that all the duplicate records were deleted successfully without any issues.
Check out How To View Table In SQL Server Management Studio
Approach-2: Using a Temporary Table
This is a great way to remove duplicates while keeping the original table structure. Follow the steps below.
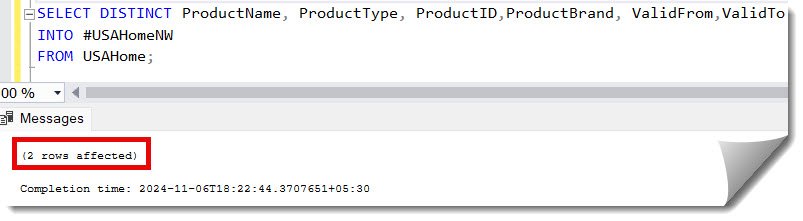
1. First, create a temp table and copy the distinct data from your original table using the below query. #USAHomeNW is the temp table, and USAHome is our original table.
SELECT DISTINCT ProductName, ProductType, ProductID
INTO #USAHomeNW
FROM USAHome;After executing the above query, we got the expected output, and only 2 distinct records got copied to the temp table.
Now, to cross-check, we can use the below select query.
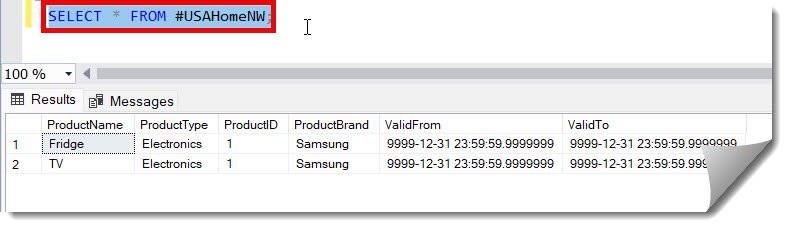
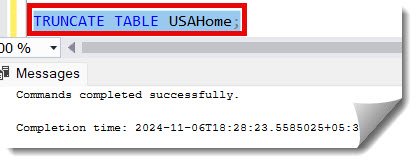
2. As the next step, let us truncate the original table, USAHome, using the query below.
TRUNCATE TABLE USAHome;After executing the above query, the data from the USAHome table was successfully deleted. Refer to the screenshot below.
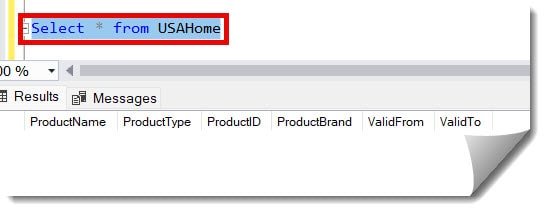
3. Using the query below, we are trying to copy the data from the #USAHomeNW temp table to the original table USAHome.
INSERT INTO USAHome
SELECT * FROM #USAHomeNW;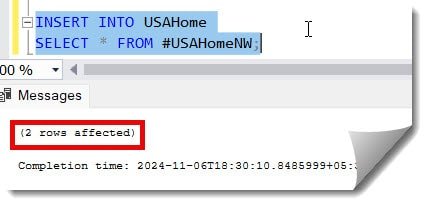
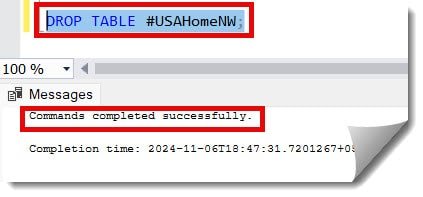
4. Finally, let us use the query below to drop the temp table, and we completed all the steps.
Approach-3 Using DISTINCT with INSERT INTO
We can also use the DISTINCT with INSERT INTO statement for this purpose.
Example
Let us consider an example of trying to copy the distinct records from the old table to the new one. Execute the below query.
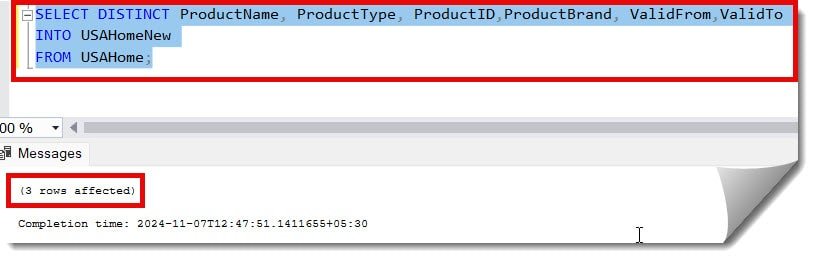
SELECT DISTINCT ProductName, ProductType, ProductID,ProductBrand, ValidFrom,ValidTo
INTO USAHomeNew
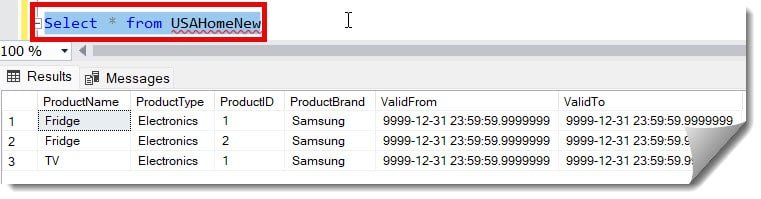
FROM USAHome;After executing the above query, we got the expected output, which is shown below.
Conclusion
Using the approaches mentioned in this article, removing duplicate data from the SQL server table is easy. Now, it is your call to choose which approach based on your requirements.
You may also like following the articles below.
- How To Save Query Results As Table In SQL Server
- How to Alter Table Column to Allow NULL in SQL Server
- How to Find Table Dependencies in SQL Server

Grey is a highly experienced and certified database expert with over 15 years of hands-on experience in designing, implementing, and managing complex database systems. Currently employed at WEX, USA, Grey has established a reputation as a go-to resource for all things related to database management, particularly in Microsoft SQL Server and Oracle environments. He is a Certified Microsoft SQL Server Professional (MCSE: Data Management and Analytics) and Oracle Certified Professional (OCP), with Extensive database performance tuning and optimization knowledge and a proven track record in designing and implementing high-availability database solutions.